Making Sense of the Verizon Data Breach Investigation Report

The Verizon Data Breach Investigation Report (DBIR) is an annual report analyzing thousands of security incidents and breaches. While it has some flaws (which I'll get to later), it's one of the few examples of people putting out good, data-driven research on security, done in a pretty well-written way, by an entity not trying to sell me something.1 Good data is something we are quite desperate for as an industry, so let's see what we can make of what we have.
Here is my take from reading the DBIR this year, adding to the coverage by Kelly Shortridge. Discussion from when it came out can be found on HN. This blog covers my key takeaways from reading it, as well as some areas of confusion or improvement for the report.
Key Takeaways
It’s British Teens, not APTs
The report has a graph on threat actors in breaches:

Here, end-user refers to when your employees mess up and email confidential information to the wrong address. Organized crime means British teenagers.
This is both good and bad news for a lot of security programs. It’s good news because state-sponsored APTs are not in your threat model, at least until you solve the simple stuff. That makes things easier; you don’t need to be able to be robust to container escapes in your kubernetes clusters or complex application vulnerabilities arising from the interaction of your nuanced internal microservice architecture. That’s bad news because we all really enjoy solving the cool shit. I get that. I also enjoy the cool shit. It just doesn’t move the needle and provide business value until you’re already robust to British teens.
Most security organizations that aren’t already incredibly mature fail at this. They overoptimize or pursue certain security goals way too intensely, past the point teenagers could reasonably attack them, at the expense of ignoring incredibly vulnerable areas. It’s one of the most common problems I see, besides pursuing completely useless controls.
You Are Almost Certainly Not Devoting Enough to SSO, MFA, and Phishing Training
Speaking of the things security teams ignore while they’re off solving cool technical problems, here are the most significant ways attackers get their initial foothold in your organization during a breach:

This is the most important graph in the report. There is no other way of reading this: basic phishing attacks and compromised credentials are by far our most likely way of getting compromised. ~75% of initial access comes from this.
You know that 75% of your security budget doesn’t go to preventing credential compromise and phishing. It’s likely not even 5%, unless you cheat by counting generic IT vaguely related to SSO, or by considering EDR phishing prevention.
I think this is for a few reasons:
It’s boring and tedious to solve. You have to spend time rolling out training, deploying FIDO or SSO, listening to people yell about that, making boring phishing training templates, and crying when people fail
It’s more exciting to go sniffing through cryptography libraries or something, so people do that instead
A perception that it’s not really possible to solve
Vendors and service providers are rather unsupportive, from the pains of the SSO tax to vendors with as much sensitive data as fucking Snowflake not allowing for enforced MFA, let alone enforcing MFA themselves
This is understandable. Glass houses and all that. I’ve also never hit double-digit percentages in spend here, even counting anything remotely related to it in IT spending. It still needs to change, for your program and for mine, especially as deepfakes of your CEO asking for gift cards are already making the rounds to your employees. Just wait til the British teens start doing good deepfakes.
Specifically, I don’t think there’s a reasonable excuse to not:
Require MFA (or SSO) everywhere there is remotely interesting data, ideally something device or FIDO-based. You don’t really need a full Yubikey here, we are preventing credentials compromise and phishing. 1Password, Microsoft Hello, or Mac Keychain passkeys are all fine.
Provide your employees with a useful password manager and train them on its use. It is always easier to use a password manager than not—show them!
Carry out regular phishing testing. This is a commoditized vendor space and very cheap and quick to roll out. Collect your employees’ credential-based scalps. Don’t shame failures, and don’t require supplemental training for failing besides pointing out the signs in the test email that they could have caught.
You’ve set up DMARC, DKIM, and SPF already, right?2
Have legitimate email security tooling and a phishing incident response process. This should at least heavily leverage your email provider’s security tooling (Google Workspace enterprise editions get you decently far). There are plenty of other vendors, too. You probably just spent too much money on some shiny cloud security thing, which doesn’t help here at all, so don’t tell me it’s not in your budget.
Have security training that isn’t a complete hack job, and touches on common phishing attempts.
Have somewhat legitimate account access restrictions and some least privilege for when accounts are compromised.
Have reasonable detections for the obvious actions post-phish for significant data in your core systems. No one should ever really download 500 million records from Snowflake, you know?
Some of these things are out of our control; I’ll probably have a blog yelling more about the SSO tax in the future. I’m hoping market conditions will improve, given recent industry trends.3 That’s just one item though; we don’t have any for the rest, and we all need to be better here.
Generative AI Doesn’t Matter to Security (Yet)
The report discusses threat actor activity leveraging GenAI, more specifically, that there really isn’t any:

Threat actor activity around GenAI seems to be very similar to every Fortune 500 company: speeding up how people can learn things (usually coding) and carry out automated tasks (usually copywriting). The DBIR writers argue this doesn’t matter:
given our Social Engineering pattern numbers from the past few years, that Phishing or Pretexting attacks don’t need to be more sophisticated to be successful against their targets
This makes sense; the British teens have been social engineering their way in just fine, and the sillier phishing attempts work well enough that adding an LLM would probably just increase costs.
More important is something that the DBIR doesn’t discuss, but its absence screamed out at me: No one is attacking AI systems either.
Despite all the clamoring for good AI security, not once are any of the attacks from the OWASP GenAI Top Ten mentioned in this report as causing an incident or breach. This makes sense to me; I’ve always felt the concern over AI security was mostly our industry chasing a shiny new thing, so we had an excuse to avoid asking dev teams to patch better.
In a recent Risky.Biz interview, Alex Cowperthwaitie of Kroll Cyber on how his company attacks AI models, Alex got very excited to find a clever prompt to make the LLM perform a request on behalf of the user to an arbitrary address, getting some sweet server-side request forgery (SSRF). That’s cool! I love that research. However, SSRF is a highly scannable vulnerability when there isn’t an LLM in front of it. Adding the LLM made it harder to find. No attacker is going to bother figuring out the right inputs for a particular LLM application to trigger one, they’ll just find a normal endpoint the company also built that is vulnerable to it. That’s much easier.
MOVEit Broke the Dataset
The report talks about MOVEit a lot. That’s fair; it happened a lot—1,567 breaches in this year’s report. Much of the 180% increase in the Exploit Vuln initial access action is driven by it this year. Kelly Shortride already put out a great write-up covering the MOVEit aspect here, so just go read that.
All I can add is that the report has a footnote claiming MOVEit is mentioned 25 times. It’s actually 30.
Malicious Dependencies Are Sillier Than I Knew
This was the funniest chart from the report:

I’m glad to learn that people trying to get free Roblox currency are at far more risk than dependency confusion attacks.
These are just the published package counts; I would love to see breach data here. As far as I know, dependency confusion is still a research-level vulnerability. There are plenty of cool blogs about it, but I can’t find any information on an actual breach caused by it. The DBIR does not mention it as actively causing any; all of these are the password stealer varieties, which makes sense given the free game currency target audience.
This makes the numbers above even sillier. I wouldn’t be surprised if all of the typosquatting and dependency confusion packages on npm are owned by bug hunters, while the free game currency and streaming packages are actually criminals.
Indeed, researchers may already have claimed all potentially interesting typos and confusing dependencies by this point. The incentives point this way; all a researcher has to do to publish a fun blog is claim a dependency and notice Microsoft downloads it once. Potential vulnerability found! An attacker has to take the time to understand the system importing a package, how it’s using that package, and how to best leverage this for exploitation. SIM swapping is easier, so the British teens are just going that route.
Also, getting someone to import a malicious package counts as social engineering and a basic web application attack. This feels wrong to me. While “free Roblox bux” packages are a bit social engineering, dependency confusion is a nuanced technical issue with how various package managers prioritize public vs private packages. That’s not really social engineering, and it’s also not really a basic web application attack.
Confusing Bits
Extortion as Social Engineering
Looking at the Social Engineering action varieties:
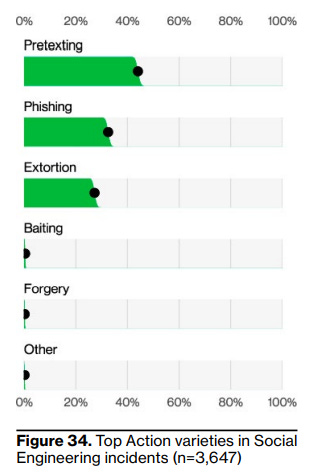
We see Extortion riding in at number 3. What exactly is meant here? The VERIS schema the DBIR uses defines extortion as “Extortion or blackmail”, so that’s helpful. Let’s try to figure it out from the Social Engineering section, where we have:
given the shift in tactics by some groups, along with the Extortion action being the final result of the breach as opposed to an initial one, this seemingly “System intrusion-y” attack now also shows up in this pattern.
and:
We’ve seen various iterations of it from the empty threats (“We’ve hacked your phone and caught you doing NSFW stuff.”) to somewhat credible threats (“Look us up. We’re super-duper hackers that’ll DDoS you.”) to very credible threats (“We’ll leak the data we took. Here are samples for you to validate.”). This year, however, Extortion showed up in spades as a result of the MOVEit breach, which affected organizations on a relatively large scale and in an extremely public fashion.
My reading is that the DBIR counts both phishing in the form of fake extortion and actual extortion after an attacker has made off with data and wants to be paid not to release it.
I dislike including extortion post-breach in the Social Engineering pattern. It’s not what anyone thinks of when they think of social engineering. At that point, it’s a business negotiation, both parties know who they are and where they stand, there’s not any more subterfuge than security vendor sales rep use. I think this hurts the report; it inflates the total Social Engineering pattern count and makes it so I have no idea how impactful fake extortion is as a social engineering tactic.
What Is a Web Application Attack?
The report contains stats on the most common hacking actions in their Basic Web Application Attack pattern:
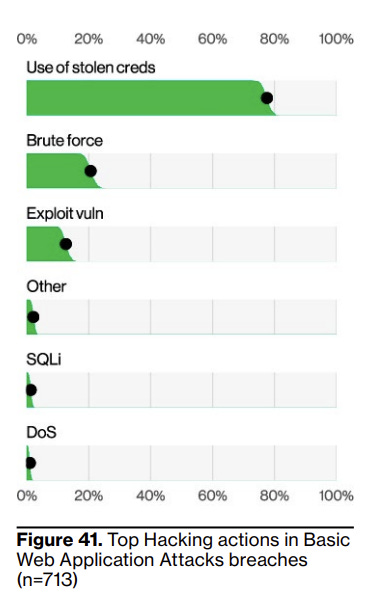
It shows that ~75% of attacks are from stolen credentials; remember, you aren’t using MFA enough, especially since ~15% are brute-forcing credentials attackers don’t have yet.
I dislike including stolen credentials in this way. It confuses the top-level trends on the web app attack pattern; most people will assume this pattern means, you know, web app vulnerabilities. Using a stolen credential feels more like attacking a user than the web application itself. Including stolen credentials in this pattern makes web app vulnerabilities seem far more significant than they are.
I’m not sure where it would be better to put them in the patterns the DBIR currently uses. Potentially Lost and Stolen assets, what is a credential if not a stolen asset. This has the same issue in that skimmers will associate the numbers with lost laptops. Perhaps this should be its own pattern entirely.
I would also like greater clarity on when something becomes a trivial, basic exploit vuln in this pattern, and a complex, cool, sexy exploit in the System Intrusion pattern.
What’s a Hack, What’s a Misconfiguration
From the report:
Misconfiguration is the next most common error and was seen in approximately 10% of breaches
And when discussing why misconfiguration’s share of breaches is on the decline:
Other factors may include that security researchers are not spending as much time on finding these systems with their screen doors flapping in the wind, and, lastly, criminals may be using the same tools historically utilized by researchers to discover these errors and exploiting them to steal data, which would result in the attack showing up with a Hacking action rather than Error.
I have no idea what this could mean. If I’m reading right, it’s considered an error if a white-hat researcher finds it and a hack if someone actually exploits it. This doesn’t make sense; a researcher finding a misconfiguration and reporting it would never be a breach, so how is this class comprising any amount of the Error share?
I would expect this to just always be both; there’s always an Error in the misconfiguration and a web server hacking in the exploitation of that misconfiguration. If any DBIR writers find this, please clarify it for me.
Industries & Regions
The report includes separate sections covering different industries and regions. For example, the state of patterns in the Information industry, which I just assume includes all SaaS companies:

And one for North America:

My confusion comes from two areas. One, the basic web application pattern including stolen credentials as I complained about earlier means I have no idea if SaaS companies are being hit by web app vulns, or by not putting MFA on their Snowflake instance. This is an important distinction!
My other issue is that I think these will be confounded datasets. The industry proportions are different across countries, so I have no idea how much industry factors impact each industry or it’s the region(s) the industry is more concentrated in. I’d appreciate controls for that confounding in both directions.
Conclusion
After listing several issues I had with the report, I’m going to end on a positive note. For all its challenges, I do really like the DBIR, the mission behind it, and the effort that’s put in. It’s the best data-driven source we have in InfoSec. It’s genuinely entertaining; I didn’t know I needed Taylor Swift and Vegeta power-level references on the same page until the DBIR gave that to me. Every single practitioner should at least skim it (and read my future blogs covering it) every year. Keep it up, friends.
We need as much data as we can get and be as data-driven as we can be. So much of this industry is based around vibes. If you don’t agree with my take from the report, that’s fine. Go read the whole thing and see where the data takes you.
I'd Love To Hear From You
Do you agree? Disagree? Intensely? Do you have any other feedback for me? Please leave a comment below; I'd love to hear it!
Yes, Verizon has a B2B security arm, but I’ve been reading this report since 2017 and have no idea what they do or sell. That’s incredibly tame by B2B security vendor standards.
These are acronyms for DNS records that prevent domain spoofing; if you don’t admin your company’s email, you don’t need to know what these stand for, and you’re happier for it.
Specifically, Snowflake has gotten a lot of flack and lost ~20% (~$9B in market cap) this month since breaches around their lack of default MFA have started flowing. That’s a very real cost to them. I don’t quite think most of this flack is deserved; I’m more hoping this is a real example of negative press and market reactions other companies will try to steer clear of.